 von
von

Nachdem wir im letzten Blogartikel die Kernkomponenten von DynamoDB, darunter die Datenorganisation in Tabellen sowie den Key-Value-Speicheransatz, ausführlich behandelt haben, lenken wir nun unseren Fokus auf fortgeschrittene Techniken zur Modellierung von Datenbeziehungen in DynamoDB. Wir beleuchten, wie DynamoDB komplexe Datenstrukturen und -beziehungen ohne traditionelle SQL-Joins darstellen kann. Dabei werden einfache und komplexe Beziehungen, wie One-to-Many und Many-to-Many, betrachtet und ihre Umsetzung in DynamoDB aufgezeigt.
Modellierung von Beziehungen
Nachdem wir uns mit den grundlegenden Konzepten von DynamoDB auseinandergesetzt haben, wollen wir nun einen genaueren Blick auf die Modellierung von Beziehungen werfen. Die Herangehensweise in DynamoDB unterscheidet sich grundlegend von der in relationalen Datenbanken. In der Welt von DynamoDB gibt es verschiedene Methoden, um Beziehungen zwischen Daten zu formulieren.
Ein entscheidender Designaspekt von DynamoDB ist die Abwesenheit von Joins, wie sie in traditionellen SQL-Datenbanken erforderlich sind. Dieser Ansatz ermöglicht es DynamoDB, die bereits erwähnten Vorteile wie hohe Performance und Skalierbarkeit zu bieten. Anstatt Elemente direkt miteinander zu verknüpfen, nutzt DynamoDB alternative Methoden zur Abbildung von Beziehungen zwischen Daten.
In DynamoDB gibt es im herkömmlichen Sinne also keine Relationen. Um inhaltliche Beziehungen zwischen Daten zu modellieren, ist eine Kombination aus der Wahl geeigneter Schlüssel und der Denormalisierung der Daten erforderlich:
-
Wahl geeigneter Schlüssel: Eine sorgfältige Auswahl und Gestaltung der Schlüssel, insbesondere des Partition Keys und des Sort Keys, ist fundamental. Diese Schlüssel ermöglichen es, logische Beziehungen zwischen verschiedenen Datenpunkten zu etablieren. Sie sind entscheidend, um zusammengehörige Daten effizient zu gruppieren und abzurufen.
-
Denormalisierung der Daten: Parallel zur Wahl der Schlüssel ist die Denormalisierung der Daten ein wichtiger Schritt. Statt Daten über mehrere Tabellen zu verteilen, werden verwandte Daten zusammen in einem Datensatz gespeichert. Diese Methode vereinfacht Abfragen: Alle relevanten Informationen können in einem einzigen Zugriff abgerufen werden und es wird so die Notwendigkeit für komplexe Abfragen vermieden.
Ergänzend zu Schlüsseln und Denormalisierung werden in DynamoDB oft auch Indexes genutzt, um Beziehungen zwischen Daten effizient zu modellieren. Indexes erweitern die Möglichkeiten der Datenabfrage und -organisation erheblich.
Einsatz eines embedded JSON-Attributs im Element
In DynamoDB kann die Modellierung von Beziehungen durch die Verwendung eines komplexen Datentyps innerhalb eines Attributs eines Elements erfolgen. Dies bedeutet, dass die Beziehungsinformationen direkt in ein JSON-Format integriert und als Teil des Elements gespeichert werden.
- Keine explizite Beziehung: Aus Sicht der Datenbank existiert damit faktisch keine Beziehung zwischen separaten Elementen. Die Beziehungsinformationen sind stattdessen innerhalb des Elements als Teil eines komplexen Attributs eingebettet.
- Einsatzbereich: Dieser Ansatz wird typischerweise verwendet, wenn ein direkter Zugriff auf die einzelnen Daten des "embedded Attributs" innerhalb der Beziehung nicht erforderlich ist, sondern stattdessen das komplette Attribut als Ganzes dargestellt oder abgefragt werden soll.
- Größenbeschränkung: Ein weiterer wichtiger Aspekt beim Einsatz von embedded JSON ist die Größenbeschränkung. Diese Methode eignet sich, solange die Datenmenge im komplexen Attribut 400 KB nicht übersteigt, was der maximalen Größe eines Elements in DynamoDB entspricht.
Beispiel

Diese Tabelle ermöglicht es, nicht nur die Seminarteilnahmen zu verfolgen, sondern bietet auch die Möglichkeit, direkt auf die Adressinformationen der Studenten zuzugreifen, ohne dass zusätzliche Abfragen oder Verknüpfungen erforderlich sind. Dadurch wird eine umfassende Sicht auf die akademischen Aktivitäten und persönlichen Daten der Studenten in einem einzigen, effizienten Datenspeicher bereitgestellt.
Angenommen, wir möchten die Daten für den Studenten "Finn Forschgeist" abrufen, dann sähe eine solche Abfrage wie folgt aus:
SELECT * FROM "University-Table"
WHERE PK = 'Student#Finn Forschgeist'
Diese Abfrage würde uns alle Einträge liefern, die Finn Forschgeist betreffen. Wir erwarten eine Antwort, die nicht nur Details zu seinem Seminar, sondern auch seine Adresse im JSON-Format enthält:
{
"PK": "Student#Finn Forschgeist",
"SK": "Seminar#Datenwolken und Cybersicherheit",
"RaumNr": "13",
"Semester": "3",
"Adresse": {
"Strasse": "Zauberweg",
"Hausnummer": "23a",
"Postleitzahl": "12345",
"Stadt": "Märchenstadt",
"Land": "Deutschland"
}
}
Benutzung desselben Partition Keys (ElementLists)
Ein weiterer Ansatz in DynamoDB, um Beziehungen zwischen Elementen zu modellieren, ist die Verwendung desselben Partition Keys für eine Liste von zusammenhängenden Elementen. Dies ermöglicht es, bei Abfragen eine Liste dieser verknüpften Elemente zurückzuliefern.
-
Verschiedene Schemas in einer Element-Liste: In dieser Liste können Elemente mit unterschiedlichen Schemas enthalten sein, wodurch eine vielfältige und flexible Datenstrukturierung innerhalb einer einzelnen Element-Liste ermöglicht wird.
-
Denormalisierung der Daten: „Fachlich“ gemeinsame Attribute werden pro Element dupliziert, was bedeutet, dass dieselben Informationen in mehreren Elementen gespeichert werden. Diese Denormalisierung ist besonders sinnvoll, wenn die Daten selten geändert werden und nur wenige Attribute dupliziert werden müssen.
-
Einsatzbereich: Diese Methode eignet sich vor allem in Szenarien, in denen Elemente nicht oder nur selten verändert werden und die Duplizierung von Daten minimiert werden kann.
Beispiel

Die dargestellte DynamoDB-Tabelle listet Seminarteilnahmen der Studenten auf. Um alle Seminare eines bestimmten Studenten, zum Beispiel "Nora Neugierig", aus der DynamoDB-Tabelle abzurufen, würden wir eine Abfrage basierend auf ihrem Partition Key durchführen.
SELECT * FROM "University-Table"
WHERE "PK" = 'Student#Nora Neugierig'
Dabei würden wir folgende Ergebnisse erhalten:
[
{
"PK": "Student#Nora Neugierig",
"SK": "Seminar#Die Kunst des Machine Learning",
"RaumNr": "42",
"Semester": "2",
"Note": "1,5"
},
{
"PK": "Student#Nora Neugierig",
"SK": "Seminar#Moderne UI Konzepte",
"RaumNr": "9",
"Semester": "2"
},
{
"PK": "Student#Nora Neugierig",
"SK": "Seminar#Rechnernetze verstehen",
"RaumNr": "15",
"Semester": "1",
"Note": "2,2"
}
]
Wenn Elemente, die unterschiedliche Schemata aufweisen, denselben Partition Key nutzen, ist es empfehlenswert, dass der Sort Key nach einem festen Muster aufgebaut wird, das mit dem Schema-Namen beginnt. Dies erlaubt es, mittels "BeginsWith"-Abfragen gezielt nur Elemente eines bestimmten Schemas abzurufen.
Beispiel
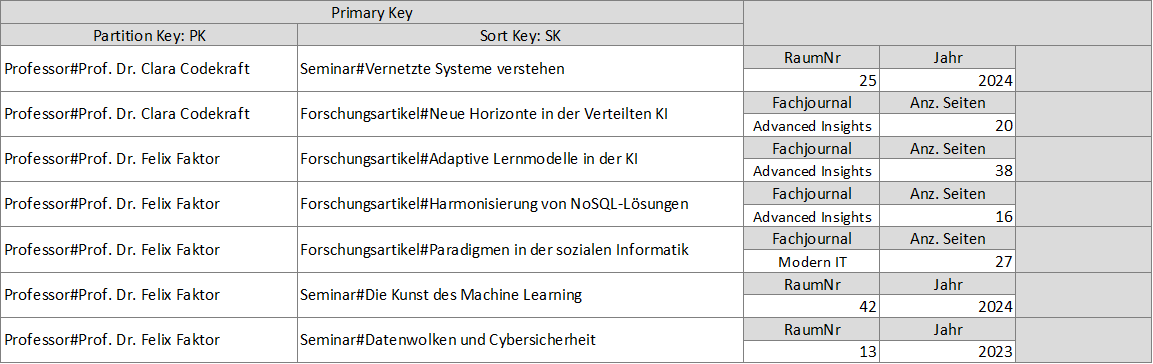
Diese DynamoDB-Tabelle dokumentiert die akademischen Aktivitäten von Professoren, darunter die Durchführung von Seminaren und die Veröffentlichung von Forschungsartikeln. Um eine Abfrage für die Forschungsartikel von Professor Codekraft in der DynamoDB-Tabelle zu erstellen, filtern die Ergebnisse auf Einträge, die Forschungsartikel repräsentieren.
SELECT * FROM "University-Table"
WHERE PK = 'Professor#Prof. Dr. Felix Faktor' AND begins_with(SK, 'Forschungsartikel#')
Dabei würden wir folgende Ergebnisse erhalten:
[
{
"PK": "Professor#Prof. Dr. Felix Faktor",
"SK": "Forschungsartikel#Adaptive Lernmodelle in der KI",
"Fachjournal": "Advanced Insights",
"Anz. Seiten": "38"
},
{
"PK": "Professor#Prof. Dr. Felix Faktor",
"SK": "Forschungsartikel#Harmonisierung von NoSQL-Lösungen",
"Fachjournal": "Advanced Insights",
"Anz. Seiten": "16"
},
{
"PK": "Professor#Prof. Dr. Felix Faktor",
"SK": "Forschungsartikel#Paradigmen in der sozialen Informatik",
"Fachjournal": "Modern IT",
"Anz. Seiten": "27"
}
]
Analog können wir nach den Seminaren von Prof. Dr. Clara Codekraft abfragen.
SELECT * FROM "University-Table"
WHERE "PK" = 'Professor#Prof. Dr. Clara Codekraft' AND begins_with("SK", 'Seminar#')
Dabei würden wir folgende Ergebnisse erhalten:
[
{
"PK": "Professor#Prof. Dr. Clara Codekraft",
"SK": "Seminar#Vernetzte Systeme verstehen",
"RaumNr": "25",
"Jahr": "2024"
}
]
Benutzung von Secondary Indexes
In DynamoDB bieten Secondary Indexes eine effektive Möglichkeit, Beziehungen zwischen Elementen zu definieren, die über den Standard des Partition Keys und Sort Keys hinausgehen. Diese Indexes ermöglichen den Zugriff auf alternative Attribute, um Verbindungen zwischen unterschiedlichen Elementen herzustellen. Ähnlich den Beziehungen, die durch denselben Partition Key entstehen, erweitern Secondary Indexes die Abfrageflexibilität, indem sie auf unterschiedliche Attribute innerhalb der Datenstruktur abzielen.
Für die Modellierung von Many-To-Many-Beziehungen sind secondary Indexes unentbehrlich. Um eine Many-To-Many-Beziehung zu modellieren, müssen Elemente mit demselben Partition Key und unterschiedlichen Sort Keys vorhanden sein, sowie Elemente mit demselben Sort Keys, aber unterschiedlichen Partition Keys. Bei der Abfrage muss jedoch immer der Partition Key angeben werden, daher kann die Many-Many Beziehung nicht allein über den Primary Key modelliert werden.
Für solche Fälle wird ein "Inverted Index" benötigt, ein Secondary Index, bei dem Partition Key und Sort Key im Vergleich zum Primary Key vertauscht sind. Dies ermöglicht die Modellierung einer Many-To-Many-Beziehung, die aus verschiedenen Richtungen abgefragt werden kann.
Beispiel

Betrachten wir dazu nochmals die DynamoDB-Tabelle der Seminarteilnahmen der Studenten. Um eine Many-to-Many-Beziehung zwischen Studenten und Seminaren zu modellieren, kann in DynamoDB ein secondary Index eingerichtet werden. Dieser Index ermöglicht es, nach Seminaren zu suchen und alle zugehörigen Studenten abzurufen.
- Name des secondary Index: "SeminarStudentsIndex"
- Partition Key: "SK" (der Sort Key aus der Haupttabelle, der den Seminarnamen enthält)
- Sort Key: "PK" (der Partition Key aus der Haupttabelle, der den Studentennamen enthält)
Um alle Studenten abzurufen, die am Seminar "Die Kunst des Machine Learning" teilnehmen, würde man den secondary Index verwenden:
SELECT * FROM "University-Table.SeminarStudentsIndex"
WHERE "SK" = 'Seminar#Die Kunst des Machine Learning'
Dabei würden wir folgende Ergebnisse erhalten:
[
{
"PK": "Student#Finn Forschgeist",
"SK": "Seminar#Die Kunst des Machine Learning"
},
{
"PK": "Student#Nora Neugierig",
"SK": "Seminar#Die Kunst des Machine Learning"
}
]
Wenn Abfragen über einen secondary Index in DynamoDB ausgeführt werden, beschränken sich die zurückgegebenen Attribute standardmäßig auf die Basisattribute des Index, also die im Index definierten Schlüsselattribute. In unserem Fall sind dies der Partition Key und der Sort Key. Um zusätzliche Attribute aus der Basistabelle in den Ergebnissen des secondary Index zu erhalten, müssen diese bei der Erstellung des Indexes explizit projiziert werden.
Schlussfolgerung: 'Queries First' als wesentliches Prinzip der Datenmodellierung
Bei der Arbeit mit DynamoDB stehen wir vor der Herausforderung, dass nicht beliebige Abfragen möglich sind. Die Datenbankanfragen sind vielmehr auf Suchvorgänge beschränkt, die entweder den Primary Keys oder den Secondary Indexes folgen. Dies unterscheidet DynamoDB grundlegend von herkömmlichen relationalen Datenbanksystemen.
Beziehungen zwischen verschiedenen Elementen werden in DynamoDB nicht durch direkte Verlinkungen erreicht, sondern durch eine geschickte Wahl der Keys und Indexes sowie durch Duplizierung der Attribute. Diese Ansätze zur Datenmodellierung in DynamoDB haben allerdings ihre Kosten, sowohl in Bezug auf die Performance als auch auf den Speicherpreis. Zudem gibt es eine maximale Grenze an Indexes, die pro Tabelle erlaubt sind, was die Flexibilität in gewisser Weise einschränkt.
Die sorgfältige Planung der Datenmodellierung ist daher von entscheidender Bedeutung. Es ist wichtig, sich im Voraus Gedanken darüber zu machen, welche Abfragen auf der Tabelle benötigt werden. Die Wahl des Primary Keys, der secondary Indexes und der Art der Beziehungen sollte so getroffen werden, dass alle Abfragen effizient und effektiv durchgeführt werden können.
Ein praktischer Ansatz ist es, mit einer Tabelle zu beginnen und die Komplexität im Auge zu behalten. Wird die Tabelle zu komplex oder sind zu viele Indexes erforderlich, sollte in Erwägung gezogen werden, die Daten auf weitere Tabellen aufzuteilen.
Fazit
Die effiziente Nutzung von DynamoDB erfordert sorgfältige Planung und ein tiefes Verständnis der Datenmodellierung. Durch geschicktes Ausnutzen der Stärken von DynamoDB und Anpassung der Modellierung an die Anwendungsanforderungen kann die volle Leistungsfähigkeit dieser NoSQL-Datenbank ausgeschöpft werden.